
Regression - Vorlesung
Contents
Regression - Vorlesung¶
Themenüberblick:
Problemstellung: Ausgleichsgerade, überbestimmtes Gleichungssystem, kleinste Fehlerquadratsumme
Matrixformulierung: OLS-Fit und -Formel
Geometrie: orthogonale Projektion, Eindeutigkeit der Lösung
Anwendungen: Prognose, polynomialer Fit, Transformationen, allgemeine quadratische Zielfunktionen, Lösen von Gleichungssystemen
zusätzliche Unterlagen: 7_Quadratische_Optimierung_Regression-scan.pdf
%pylab inline
%config InlineBackend.figure_format = 'svg'
%pylab is deprecated, use %matplotlib inline and import the required libraries.
Populating the interactive namespace from numpy and matplotlib
Problemstellung¶
Beispiel: Ausgleichsgerade
Wir beginnen mit dem klassischen Beispiel des Fits einer Geraden durch \(n\) Datenpunkte.
n = 13 # number of data points
t = linspace(1, 10, num = n) # time points measurements
noise = 0.4*randn(n) # noise in measurement values
y = 2 + 0.5*t + noise # measurement values: line + noise
figure(figsize=(5,3))
plot(t, y, 'o')
xlabel('t')
ylabel('y')
grid(True)

Ziel: Fit einer Geraden \(y(t) = d + kt\) durch die Datenpunkte \((t_i,y_i)\), sodass der “Fehler”, der noch zu definieren ist, klein ist. In anderen Worten: Finde die “optimalen” Werte für \(d\) und \(k\) aus den Datenpunkten.
Vorgehensweise: Wir formulieren das lineare Gleichungssystem
für die zwei unbekannten Größen \(d\) und \(k\) als Matrixgleichung \(Ax=b\):
Das lineare Gleichungssystem ist typischer Weise nicht lösbar, da meist keine Gerade durch alle Datenpunkte legbar ist. Stattdessen soll der “Fehler” minimiert werden. Wir definieren als \(i\)-ten Einzelfehler \(e_i\) die \(y\)-Differenz zwischen dem Fit \(\hat{y}_i := d + kt_i\) und dem zugehörigen Datenwert \(y_i\), d. h., \(e_i = d + kt_i - y_i\). Der Fehlervektor \(e\) besteht aus allen \(n\) Einzelfehlern. In Matrixnotation lässt er sich leicht durch \(e = Ax - b\) berechnen. Wir verlangen, dass der Fehlervektor minimale Länge haben soll. Das heißt \(\lVert e \rVert = \sqrt{e_1^2 + e_2^2 + \ldots + e_n^2}\) soll minimal sein, was äquivalent ist zu \(\lVert e \rVert^2 = e_1^2 + e_2^2 + \ldots + e_n^2\) soll minimal sein. In Matrixnotation: \(\lVert e \rVert = \lVert Ax - b \rVert\). Diese Vorgehensweise heißt “Methode der kleinsten Fehlerquadrate”, andere Bezeichnungen sind “Regression” und “least squares”.
Matrixformulierung¶
Formulierung des allgemeinen Optimierungsproblems:
Das obige Optimierungsproblem läßt sich in Matrixform schreiben als
Umgekehrt wird jedes Optimierungsproblem, das sich als \(\text{min. } \lVert Ax - b \rVert\) schreiben läßt auch als Regressionsproblem bezeichnet.
Hinweis: Die Probleme \(\text{min. } \lVert Ax - b \rVert\) und \(\text{min. } \lVert Ax - b \rVert^2\) sind äquivalent.
Lösung in Matrixform:
Falls der Rang der Matrix \(A\) maximal ist, dann hat das Regressionsproblem die eindeutige Lösung
Der optimale Vektor \(\hat{x}\) ist auch Lösung des Gleichungssystems
Die Gleichungen dieses Gleichungssystems heißen Normalgleichungen.
Lösungsvarianten in Python:
über die Formel \(\hat{x} = (A^T A)^{-1}A^T b\)
Lösen der Normalgleichungen mit
solvemit dem Befehl
lstsq
col_of_ones = ones(n)
A = stack((col_of_ones, t), axis=1)
b = y.reshape(13,1)
# print(A)
# print(b)
# via Formel
x_hat_1 = inv(A.T @ A) @ A.T @ b
print(x_hat_1)
# via Normalgleichungen
x_hat_2 = solve(A.T @ A, A.T @ b)
print(x_hat_2)
# via lstsq
x_hat_3 = lstsq(A, b, rcond=None)[0]
print(x_hat_3)
[[1.68007874]
[0.50884642]]
[[1.68007874]
[0.50884642]]
[[1.68007874]
[0.50884642]]
# Fit A*x_hat:
y_hat = A @ x_hat_1 # same as y_hat = x_hat_1[0] + x_hat_1[1]*t
figure(figsize=(5,3))
plot(t, y, 'o', label='data')
plot(t, y_hat, 'o-', label='fit')
xlabel('t')
ylabel('y')
legend(loc='best')
grid(True)

Geometrie¶
Orthogonale Projektion:
Wir betrachten das Matrixprodukt \(Ax\) als Linearkombination der \(m\) Spalten \(a_i\) von \(A\) mit den Komponenten von \(x\):
Diese Linearkombination der Vektoren \(a_i\) im \(\mathbb{R}^n\) soll durch optimale Wahl der \(x_i\) dem Vektor \(b\in\mathbb{R}^n\) möglichst nahe kommen, sodass der Differenzvektor \(e = Ax-b\) eine minimale Länge hat.
Für den Fall \(n=3\) und \(m=2\) läßt sich die Situation wie folgt grafisch darstellen:
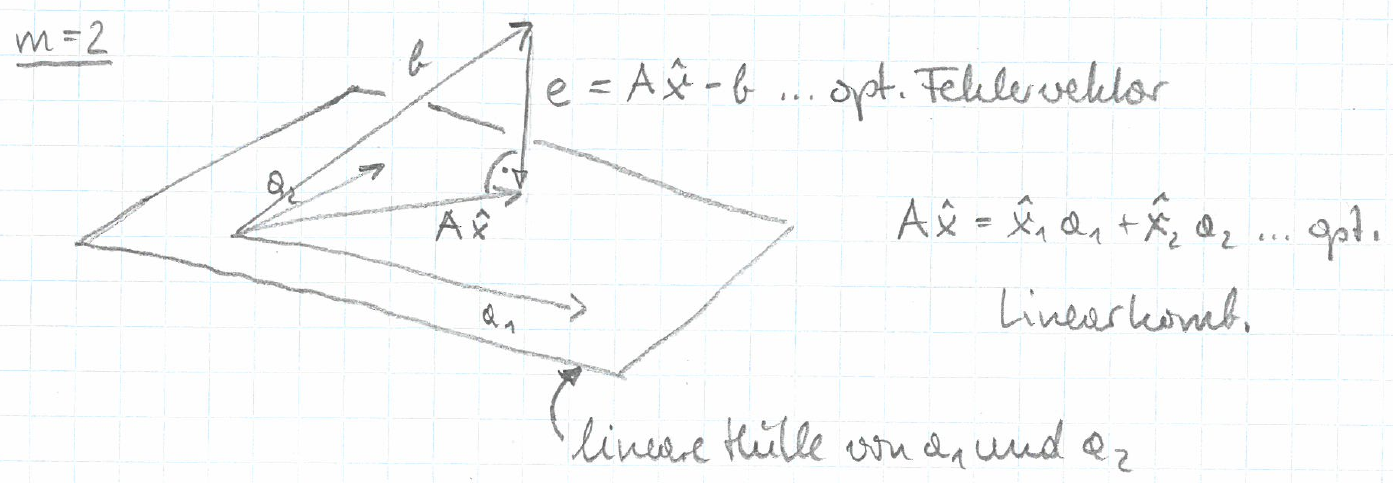
Die Abbildung suggeriert, dass die optimale Linearkombination der orthogonalen Projektion von \(b\) auf die von den Spalten \(a_i\) aufgespannte Ebene entspricht.
Wir zeigen nun, dass diese Intuition in allen Dimensionen \(n\) und \(m\) stimmt, sofern der Rang der Matrix \(A\) maximal ist und deshalb \(A^T A\) invertierbar ist. Dazu überprüfen wir, ob der Fit \(A\hat{x}\) und der Fehler \(e=A\hat{x}-b\) rechtwinklig sind, indem wir das innere Produkt der beiden berechnen:
Bemerkungen:
Wenn die Spalten \(a_i\) von \(A\) linear unabhängig sind und dadurch der Rang von \(A\) maximal ist, dann ist jeder Vektor in der von den Spalten aufgespannten linearen Hülle eindeutig als Linearkombination der Spalten schreibbar. Der optimale Fit \(A\hat{x}\) ist als orthogonale Projektion in diese lineare Hülle somit eindeutig als Linearkombination der Spalten schreibbar. Die Linearkombinationskoeffizienten \(\hat{x}_i\), die die Lösung \(\hat{x}\) bilden, sind in diesem Fall also eindeutig.
Im Fall, dass die Spalten linear abhängig sind und dadurch der Rang von \(A\) nicht maximal ist, gibt es immer noch einen eindeutigen optimalen Fit durch die orthogonale Projektion in die lineare Hülle der Spalten, aber er ist nicht eindeutig als Linearkombination der Spalten schreibbar. Es gibt dann unendlich viele optimale \(\hat{x}\), die alle denselben optimalen Fit \(A\hat{x}\) bilden.
Anwendungen¶
Prognose:
Regressionen werden sehr oft für Prognosen verwendet: Die Spalten der \(n\times m\) Matrix \(A\) bilden dabei die jeweils \(n\) historischen Werte der \(m\) erklärenden Größen. Nach dem Fit an die \(n\) historischen Werte \(b\) der zu erklärenden Größe stehen die optimalen Koeffizienten im Vektor \(\hat{x}\) zur Verfügung. Damit können neue Werte der zu erklärenden Größe berechnet werden, indem die zugehörigen neuen Werte der \(m\) erklärenden Größen mit den Koeffizienten des Vektors \(\hat{x}\) multipliziert werden.
t_new = array([11, 12, 13])
col_of_ones_new = ones(3)
A_new = stack((col_of_ones_new, t_new), axis=1)
y_new = A_new @ x_hat_1 # same as y_new = x_hat_1[0] + x_hat_1[1]*t_new
figure(figsize=(5,3))
plot(t, y, 'o', label='data')
plot(t_new, y_new, 'o-', label='forecast')
xlabel('t')
ylabel('y')
legend(loc='best')
grid(True)

Polynomialer Fit:
Verallgemeinerung der Ausgleichsgerade als Polynom 1. Ordnung auf z. B. Polynome 3. Ordnung mit gesuchten Koeffizienten \(c_0\), \(c_1\), \(c_2\) und \(c_3\):
als Matrixgleichung \(Ax=b\):
Die optimalen Koeffizienten sind Lösung des Regressionsproblems \(\text{min. } \lVert Ax - b \rVert\).
Transformationen:
Beispiel: Das exponentielle Wachstumsmodell
mit unbekannten Parametern \(\alpha\) und \(t_0\) kann durch Logarithmieren zu einem linearen Modell
transformiert werden. Das resultierende lineare Modell kann als Ausgleichsgerade mittels Regression behandelt werden. Dabei entspricht \(d=-t_0 \log(\alpha)\) und \(k=\log(\alpha)\).
Quadratische Zielfunktionen:
Jede quadratische, skalare Zielfunktion \(g(x)\) mit \(x\in\mathbb{R}^n\) kann (bis auf einen für die Optimierung irrelevanten additiven Term) in der Regressionsform \(\lVert Ax - b \rVert^2\) geschrieben und somit mittels Regression behandelt werden.
Beispiel:
Lösen von Gleichungssystemen:
Für ein lineares Gleichungssystem \(Ax=b\) liefert die Regressionslösung \(\hat{x}\) eine Lösung, falls \(Ax=b\) mindestens eine Lösung hat. Falls keine Lösung existiert, liefert die Regressionslösung \(\hat{x}\) keine Lösung des lineares Gleichungssystem \(Ax=b\) sondern die Least-Squares-Approximation!