Code
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import pyomo.environ as pyoDrei Kraftwerkstypen (KT) mit der selben Nennleistung können an 4 verschiedenen Standorten (SO) errichtet werden. Von jedem Kraftwerkstyp soll genau ein Kraftwerk errichtet werden. An jedem Standort kann nur ein Kraftwerk errichtet werden. Die Betriebskosten unterscheiden sich je nach Kraftwerkstyp und Standort gemäß der folgenden Tabelle:
| KT,SO | SO1 | SO2 | SO3 | SO4 |
|---|---|---|---|---|
| KT1 | 13 | 16 | 12 | 11 |
| KT2 | 15 | - | 13 | 20 |
| KT3 | 5 | 7 | 10 | 6 |
Der Kraftwerkstyp 2 ist für den Standort 2 ungeeignet. Welcher Kraftwerkstyp soll an welchem Standort errichtet werden, sodass die Gesamtkosten minimal sind?
Um dieses Problem als Zuordnungsproblem zu formulieren, müssen wir einen Dummy-Kraftwerkstyp KT4 einführen. Zudem werden extrem hohe Betriebskosten \(M\) (das ist der Trick der Big-M-Methode) für Kraftwerkstyp 2 am Standort 2 angesetzt, um diese Zuordnung in der optimalen Lösung zu verhindern. Das resultierende Zuordnungsproblem hat dann die Kostentabelle
| KT,SO | SO1 | SO2 | SO3 | SO4 |
|---|---|---|---|---|
| KT1 | 13 | 16 | 12 | 11 |
| KT2 | 15 | M | 13 | 20 |
| KT3 | 5 | 7 | 10 | 6 |
| KT4 | 0 | 0 | 0 | 0 |
Quelle: Hillier, Lieberman: Introduction to Operations Research. 10th edition, 2015. p. 348 ff.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import pyomo.environ as pyoSiehe Zuordnungsproblem_Beispiel.xlsx
# read cost table data from file:
df = pd.read_excel("daten/Zuordnungsproblem_Beispiel.xlsx", index_col=0)
df| SO1 | SO2 | SO3 | SO4 | |
|---|---|---|---|---|
| KT1 | 13 | 16 | 12 | 11 |
| KT2 | 15 | 99999 | 13 | 20 |
| KT3 | 5 | 7 | 10 | 6 |
| KT4 | 0 | 0 | 0 | 0 |
Wir stellen die Daten des Zuordnungsproblems (analog zum Transportproblem) in einem ungerichteten Graphen dar, in dem jede Quelle (Kraftwerkstypen) mit jedem Ziel (Standorte) verbunden ist. Die Kantenkosten sind die Kosten der Zuordnung:
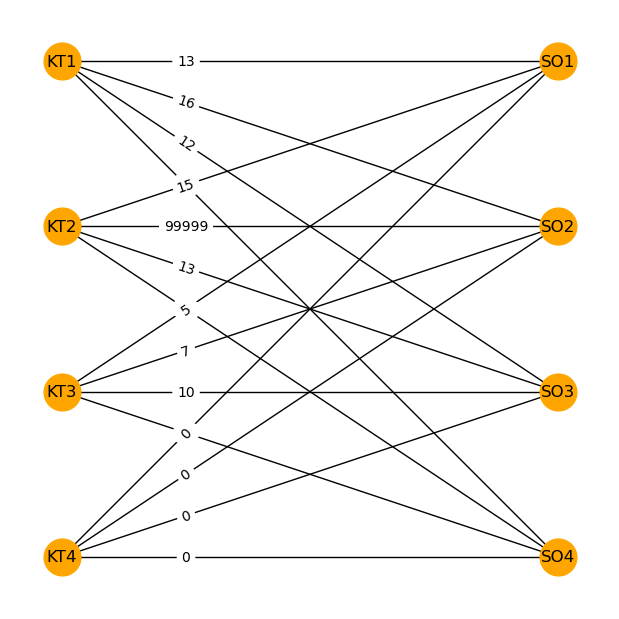
Für die Optimierung erhält jede Kante eine binäre Flussvariable, die angibt, ob die Quelle dem Ziel zugeordnet wird oder nicht. Die Zielfunktion ist die Summe der Zuordnungskosten der Kante multipliziert mit der zugehörigen binären Variablen. Die Nebenbedingungen fixieren, dass jede Quelle genau einem Ziel zugewiesen wird und jedes Ziel genau eine Quelle erhält.
# index and column names as lists:
sources = df.index.tolist()
targets = df.columns.tolist()
c = df.loc[sources, targets]model = pyo.ConcreteModel()
model.S = pyo.Set(initialize=sources) # set of sources (plants)
model.T = pyo.Set(initialize=targets) # set of targets (warehouses)
if True: # use integrality constraint:
print("using integrality constraint")
model.x = pyo.Var(model.S, model.T, domain=pyo.Binary)
else: # relax the integrality constraint:
print("relaxing integrality constraint")
model.x = pyo.Var(model.S, model.T, domain=pyo.NonNegativeReals)
model.cost = pyo.Objective(expr=
sum(model.x[s, t]*c.loc[s, t] for s in model.S for t in model.T),
sense=pyo.minimize)
@model.Constraint(model.S)
def demand_constraint(model, s):
return sum(model.x[s, t] for t in model.T) == 1
@model.Constraint(model.T)
def production_constraint(model, t):
return sum(model.x[s, t] for s in model.S) == 1
# model.pprint()using integrality constraintsolver = pyo.SolverFactory('cbc')
# solver = pyo.SolverFactory('glpk')
# solver = pyo.SolverFactory('appsi_highs')
# solver = pyo.SolverFactory('gurobi')
results = solver.solve(model, tee=False)
print(f"status = {results.solver.status}")
print(f"minimal cost = {pyo.value(model.cost):.2f} EUR")status = ok
minimal cost = 29.00 EURx_sol_dict = model.x.extract_values()
x_sol_dict{('KT1', 'SO1'): 0.0,
('KT1', 'SO2'): 0.0,
('KT1', 'SO3'): 0.0,
('KT1', 'SO4'): 1.0,
('KT2', 'SO1'): 0.0,
('KT2', 'SO2'): 0.0,
('KT2', 'SO3'): 1.0,
('KT2', 'SO4'): 0.0,
('KT3', 'SO1'): 1.0,
('KT3', 'SO2'): 0.0,
('KT3', 'SO3'): 0.0,
('KT3', 'SO4'): 0.0,
('KT4', 'SO1'): 0.0,
('KT4', 'SO2'): 1.0,
('KT4', 'SO3'): 0.0,
('KT4', 'SO4'): 0.0}x_sol_df = pd.DataFrame(index=sources, columns=targets)
for item in x_sol_dict:
x_sol_df.loc[item[0], item[1]] = x_sol_dict[item]
x_sol_df| SO1 | SO2 | SO3 | SO4 | |
|---|---|---|---|---|
| KT1 | 0.0 | 0.0 | 0.0 | 1.0 |
| KT2 | 0.0 | 0.0 | 1.0 | 0.0 |
| KT3 | 1.0 | 0.0 | 0.0 | 0.0 |
| KT4 | 0.0 | 1.0 | 0.0 | 0.0 |